LLM的训练历程
非神经网络时代的完全监督学习(特征工程)
- 利用特定的规则,统计学的模型对特征进行匹配和利用,进而完成特定的NLP任务——>常见方法:贝叶斯隐马尔可夫模型等
基于神经网络的完全监督学习 (架构工程)
- 不用手动设置特征和规则,节省了人力资源,但需要人工设计合适的神经网络架构对数据集进行训练——>常见方法:CNN、RNN、Transformer等
预训练+精调范式(目标工程)
- 现在数据集上进行训练,然后里用预训练好的模型在下游任务的特定数据集上进行fine-tuning,使模型更适应下游任务
预训练+提示——预测范式(prompt工程)
- 将下游任务的建模方式重新定义,通过合适的prompt来实现直接在预训练模型上解决下游任务,这种模型需要极少的(甚至为零)下游任务数据,使小样本、零样本学习成为可能
LLM主要类别介绍
Transformer
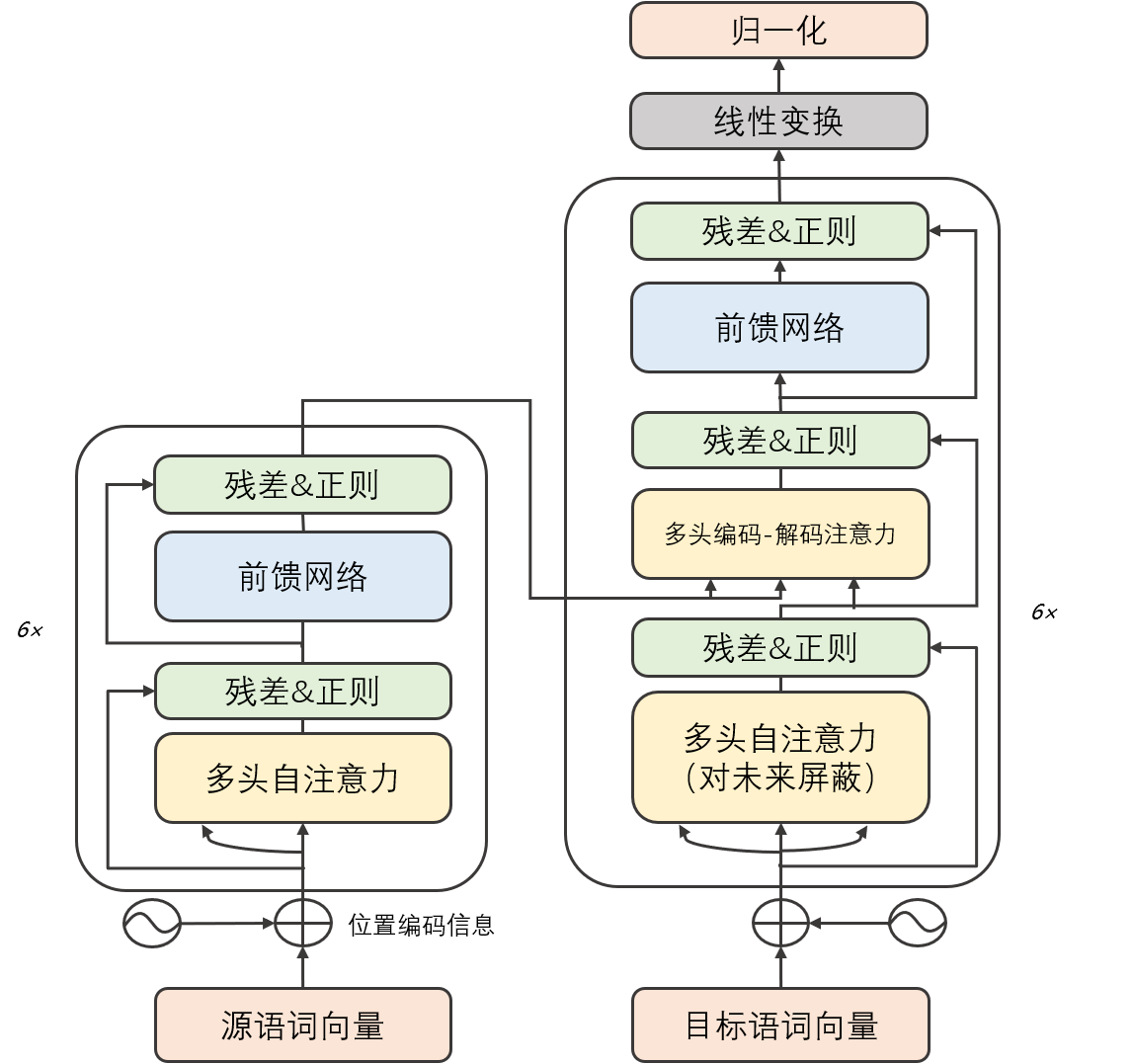
分类:
- BERT:只使用了transformer编码器encoder部分而完全舍弃解码器decoder
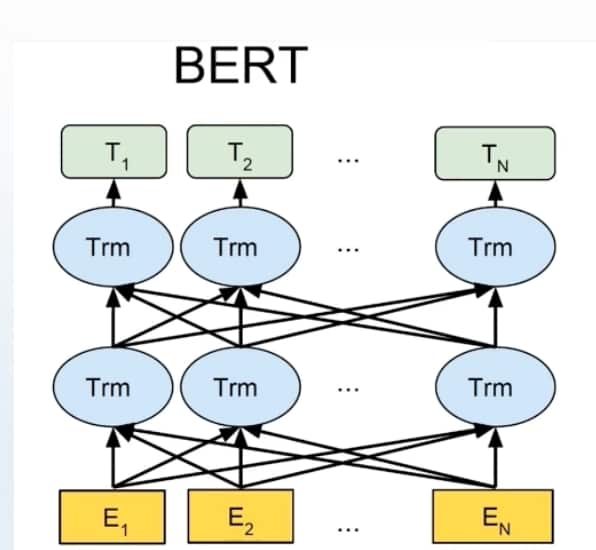
- 预训练任务:
- Masked LM:随机掩盖掉一些词然后联系上下文进行预测该词(完形填空)
- Next Sentence Prediction:判断第二个句子是不是第一个句子的下文
- 预训练任务:
- GPT:采用了transformer经典架构的解码器decoder但是未完全照搬(去除了中间段的muti- head attention,并且相比经典架构6个decoder block,GPT采用了12个)
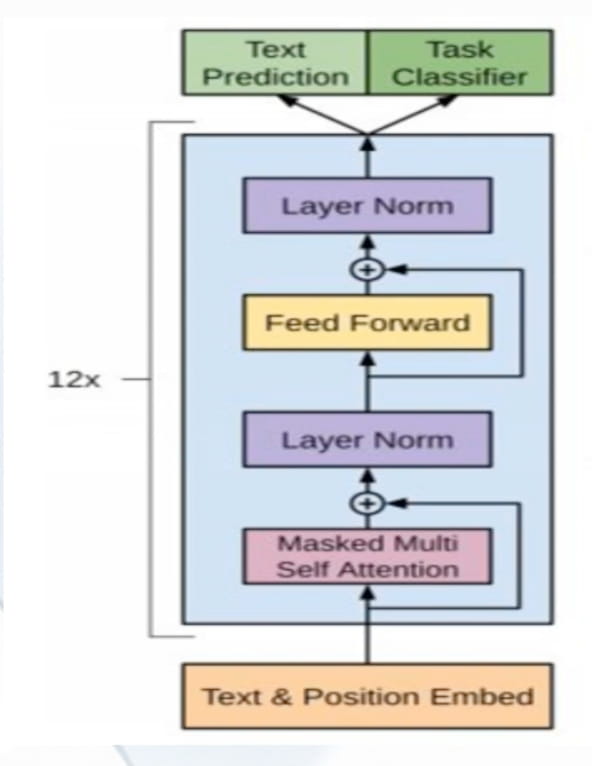
- 预训练任务:
- 无监督预训练(语言建模):模型根据前面的文本来预测文本的下一个词
- 训练目标:最大似然估计(最大化正确预测下一个词的概率
- 预训练任务:
- T5:
- 相当于将所有任务都转化为文本转化任务,进行任务统一的结构
- 主题架构还是Transformer,但采用简化版的规范化层;使用一种简单版的相对位置编码, 在同一层内不同注意头的位置编码都是独立学习的
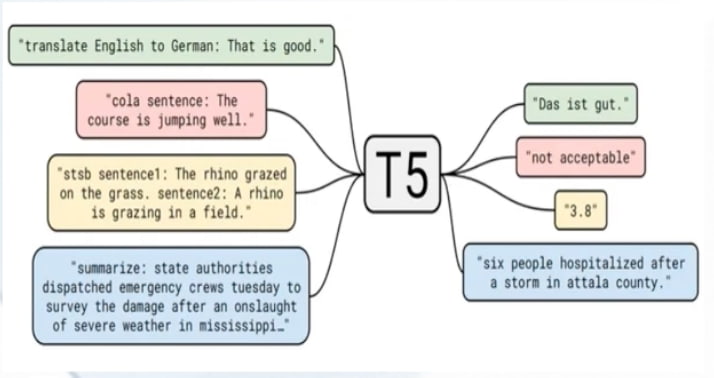
- 预训练任务:
- 自监督预训练:Masked LM(同BERT)
- 多任务预训练:利用不同任务的标注数据进行有监督的多任务的预训练